Feeding the Model —with School Data
IN THIS LESSON
Learning Focus: Understanding the critical roles of training, validation, and test data in building a reliable ML model.
Essential Question: How can we be sure an AI model has actually learned, and isn't just "memorising" the answers?

The Donut Tasting Championship
This is an analogy to help explain the data-splitting process. Imagine training a donut taster (our model).
Training Data: They taste thousands of donuts to learn what makes a "prize-winning" donut. This is the bulk of their experience.
Validation Data: Periodically, they taste a smaller, different batch to check their progress and fine-tune their taste buds. This helps prevent them from only liking one type of donut.
Test Data: Finally, at the championship, they taste a completely new set of donuts they've never seen before. Their performance here is the true test of their skill.
Try building your own donut dataset in the app below
Core Concepts Explained: Overfitting - When Learning Goes Wrong
The donut taster who "trains" only on strawberry-filled donuts. They become an expert on that one type but fail miserably when asked to judge a chocolate cruller. The model has "memorised" the training data instead of learning the general characteristics of a good donut.

Overfitting occurs when an AI model learns its training data too well. Instead of learning the general patterns, it memorises the specific details and even the noise in the data it was shown.
Analogy: Imagine a student preparing for a math test. Instead of learning the formulas (the general pattern), they just memorise the exact answers to the 10 practice questions. They would get 100% on the practice test, but when the real test has slightly different questions, they wouldn't know how to answer them. The student "overfit" the practice material.
Result: An overfit model performs exceptionally well on the data it was trained on but fails to make accurate predictions when it sees new, real-world data.
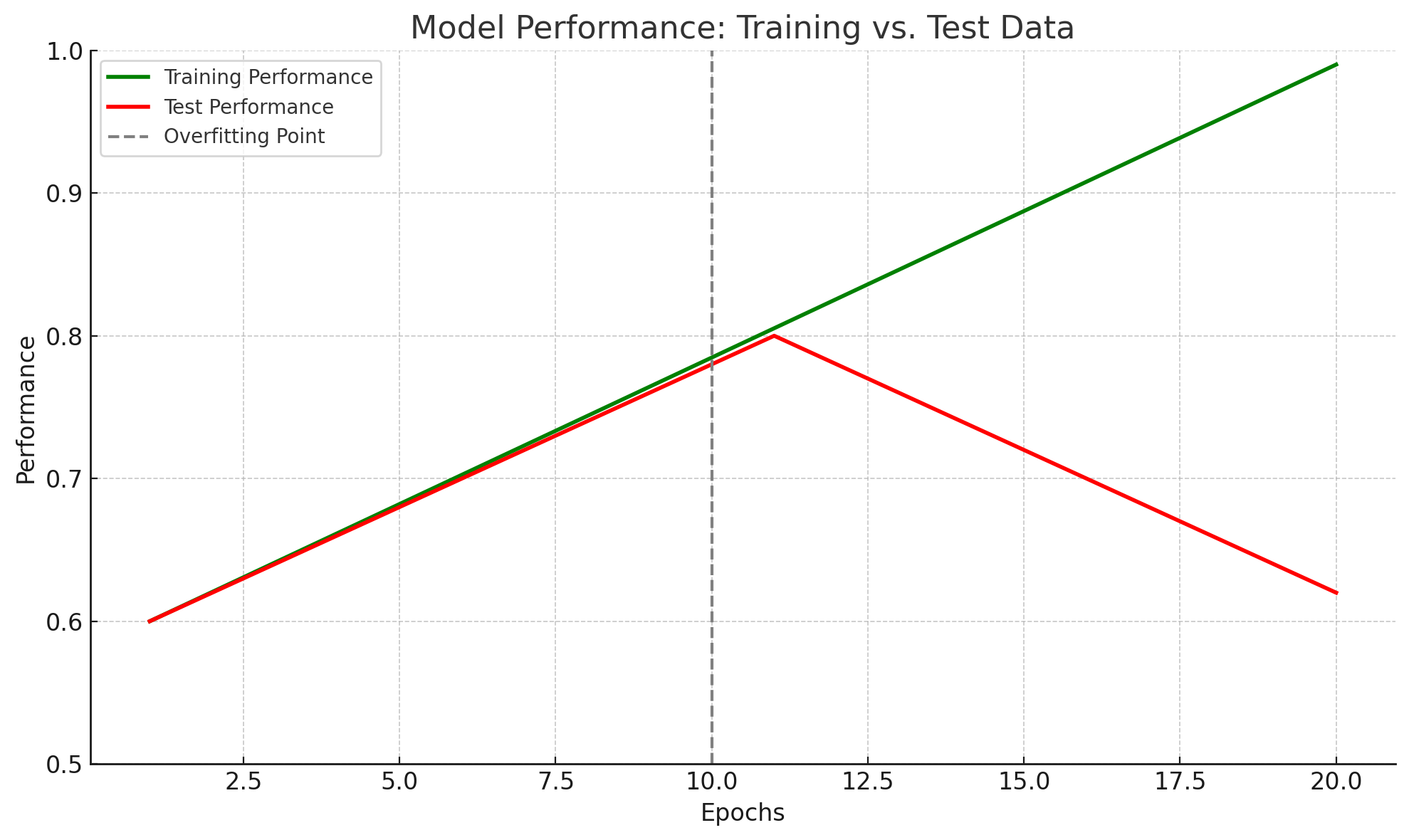
Generalisation is the goal of AI training. It refers to the model's ability to apply what it has learned from the training data and perform accurately on new, unseen data.
Analogy: This is the student who learns the actual math formulas (the general pattern). Because they understand the underlying concepts, they can solve any new problem on the real test, even if they've never seen that exact question before. Their knowledge can "generalise" to new situations.
Result: A model that generalises well is useful and reliable because it has learned the fundamental patterns in the data, not just the specific examples it was fed. It's the opposite of overfitting.
Reflection
In the 'Build Your Donut Dataset' activity, what was your strategy for choosing which donuts went into the test set? Why is it crucial that this set represents a variety of donuts?